How to Extract Metadata from a PDF File – Step by Step


A PDF file has multiple properties that are stored in the metadata section. These properties are author, subject, title, etc. These properties are useful for you to know more about the document. Users who want to extract metadata from PDF documents can easily do this by following the methods mentioned below. If you are looking for a way to get metadata from a PDF file, then this article will help you in this regard.
Method 1: Manually Extract Metadata from PDF Document
In this method, you will know how to pull metadata from PDF file using Adobe Acrobat Reader. This method is feasible on both the free and pro versions of the Adobe application.
- Open a PDF file using Adobe Acrobat Reader.
- In old Adobe Acrobat Reader, click “File” in the upper left corner.
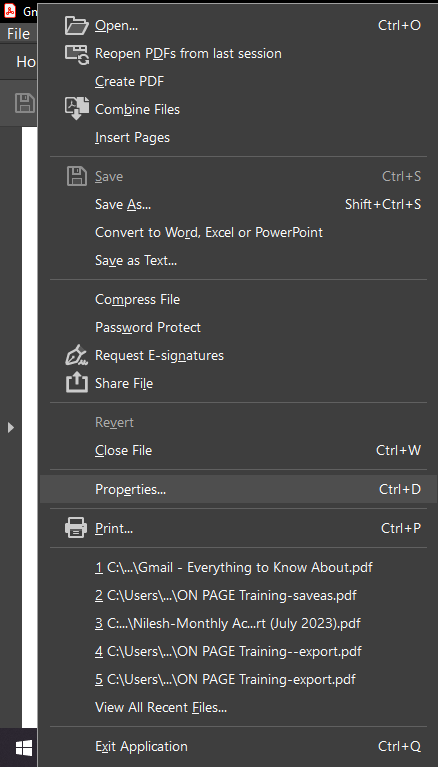
- In the new Adobe Acrobat Reader, click “Menu” in the upper left corner.
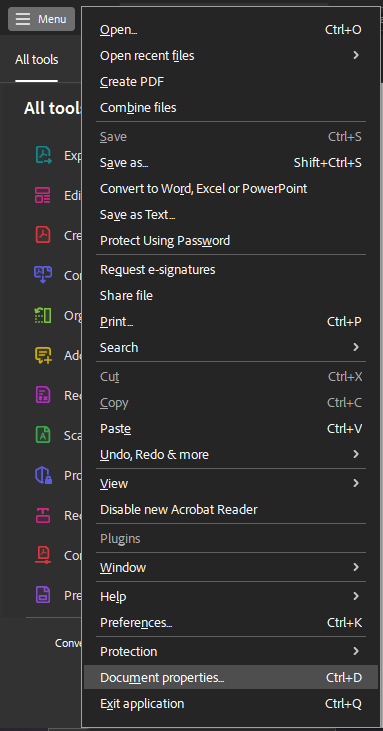
- Select “Properties/Document Properties” from the drop-down menu.
- In the Document Properties dialog box, click on the Description tab to access Title, Author, Subject, Keywords, and other metadata information.
- Copy the information and paste it into another document/text file to save it.
Method 2: Get Metadata from Multiple PDF Files At Once
This method is not only feasible for extracting metadata from a single PDF file but also from multiple PDF files at once. Users can use this Offline PDF Extractor Software to get metadata from PDF documents in bulk. It provides you with a distinct option to save the extracted information in PDF, DOC, or DOCX format. You can save the metadata at your desired location.
This software has the capability to extract data items from PDF files other than metadata like text, bookmarks, images, audio, video, etc.
Here’s how to pull metadata from PDF files in bulk:
- Launch the tool on your PC.
- Click on the Add File button and select all the PDF files from which you want to extract metadata.
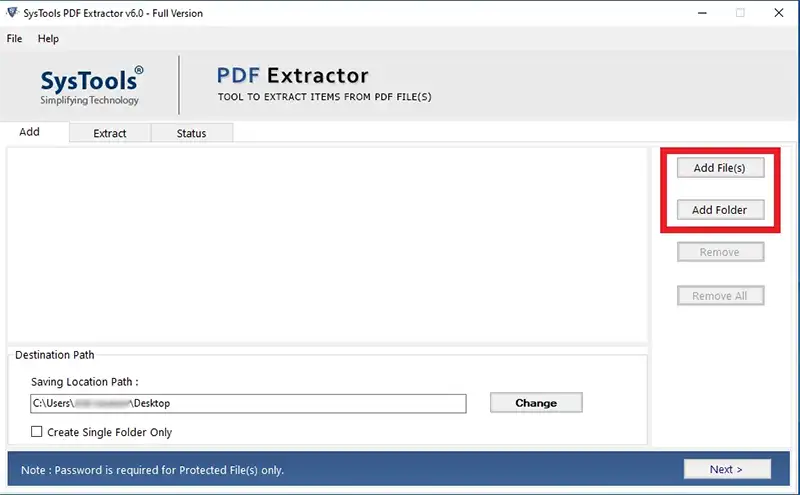
- After adding the PDF files, click on the Change button to select the destination location to save the metadata information.
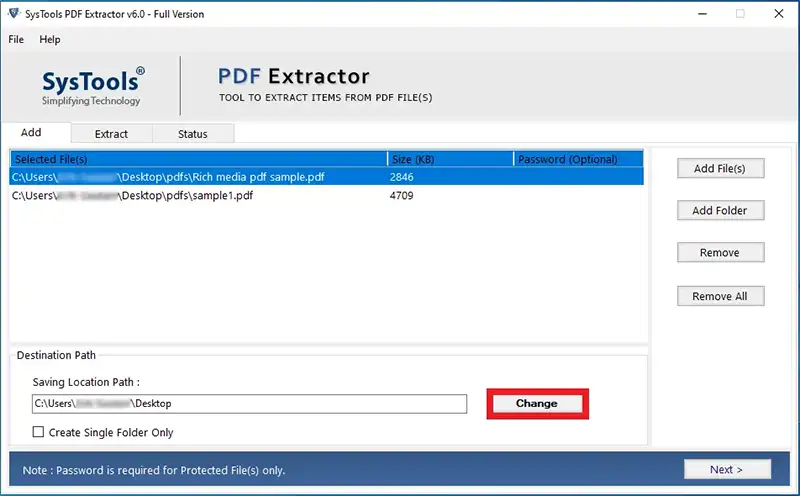
- Go to the next window and uncheck the boxes in all tabs except Metadata.
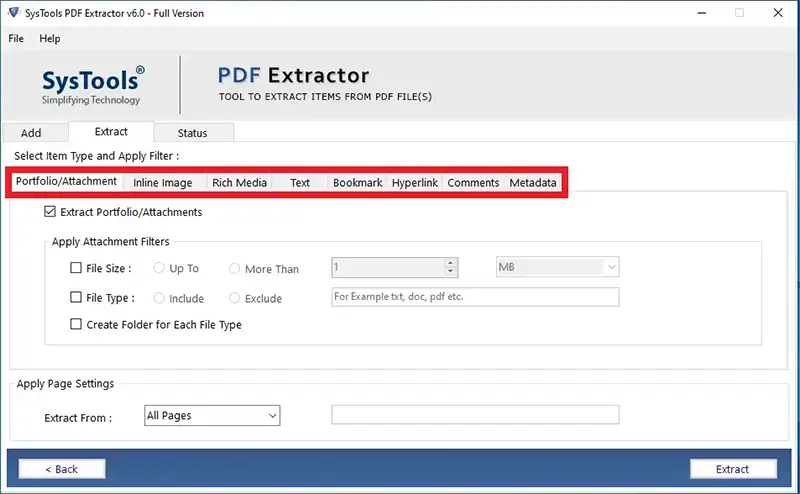
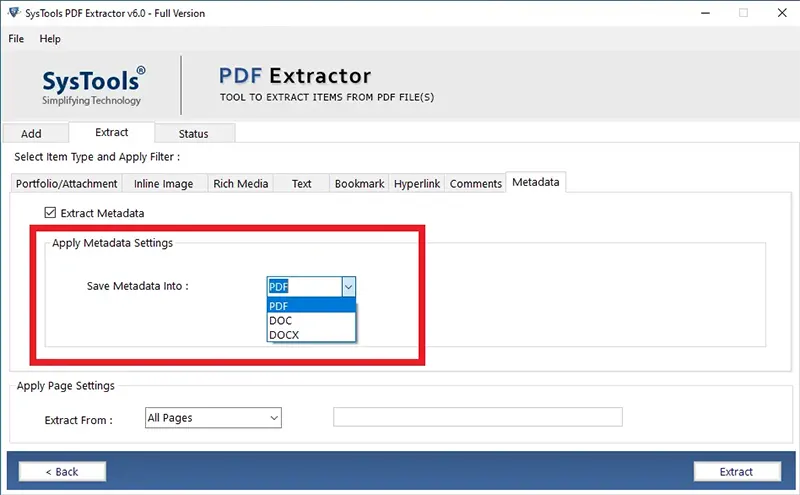
- Choose the document format (PDF, DOC, DOCX) in which you want to save the metadata properties.
- Once done, click on the Extract button to start the process.
- Wait for the process to complete and click on Ok.
- That’s it. You can check the destination location to find your metadata information file.
Method 3: Pull Metadata from PDF Using Python
If users have knowledge of Python programming language, then they can use it to extract metadata from PDF file. For this, we will use the Pypdf2 library.
- Install Python on your system.
- Install the Pypdf2 library by running the following command in the command prompt (Cmd):
pip install PyPDF2
- Now, create a Python script to pull metadata from your PDF file.
import PyPDF2
def extract_pdf_metadata(pdf_file):
with open(pdf_file, 'rb') as file:
pdf = PyPDF2.PdfFileReader(file)
info = pdf.getDocumentInfo()
print("Title:", info.title)
print("Author:", info.author)
print("Subject:", info.subject)
print("Keywords:", info.keywords)
print("Creation Date:", info.created)
print("Modification Date:", info.modDate)
if __name__ == "__main__":
pdf_file = 'your_file.pdf' # Replace with the path to your PDF file
extract_pdf_metadata(pdf_file)
- Now, print the metadata information in the console. Open your command prompt or terminal, navigate to the folder containing the script, and run:
python pdf_metadata.py
Final Thoughts
This tutorial has shown you how to extract metadata from PDF files using Adobe, Python, and without Adobe. You can choose the method that suits your needs and expertise. The manual methods are quick, but not suitable for processing multiple PDF files. While the automated software can easily get metadata from multiple PDF documents in bulk.
FAQs
Q1 What is metadata in a PDF document?
Metadata in a PDF file shows descriptive information about the document, such as its title, authors, date of creation, keywords, and so on. It helps users and software understand PDF content and format.
Q2 What metadata can be viewed in a PDF?
Common metadata fields include title, author, title, keywords, creation date, modification date, creator, and more. The available metadata fields can vary depending on how the PDF was created.
Q3 Can I edit or update PDF metadata?
Yes, you can edit PDF metadata using software like Adobe Acrobat. This allows you to edit the title, author, keywords, and other information after the PDF is created.
Q4 Why is it important to get metadata from PDFs?
Extracting metadata from PDFs is important for organizing, sharing, and searching large collections of documents.
